Stories from the War Room: the DNS Debacle (nur auf Englisch)
After a few days without major issues, most of the team started feeling relieved and enjoying a fresh start to the week. However, tech issues also know about Mondays, and a little mistake can create huge problems. This is our third Story from the War Room, and we call it the DNS Debacle - yeah, the title spoils it a bit, but as some people would say, ‘It is always the DNS’.
-------
On June 24th, at 16:45 UTC, some players began to encounter login issues. They were abruptly disconnected and found themselves unable to log back in. As the affected players were scattered across various regions, shards, and zones, our monitoring systems only detected a slight decrease in user activity and did not sound an alarm. Keeping a watchful eye on our active Discord community, one of the Mainframers spotted the troubling trend and quickly decided to raise the alarm and activate the War Room.
------
By 17:00 UTC, we were in diagnostic mode. The issue was with logins, and it was affecting a significant (and growing) portion of our player base. Although we still had a large number of active players, the curve was flatlining or starting to decline—right when it should be on the rise.
Our initial investigation through monitoring, metrics, graphs, and alerts pointed to a couple of potential smoking guns. One of our central services that handles logins was seeing increased CPU load, and our main authentication system logs were spewing errors. Additionally, we noticed issues with the system handling entitlements (determining who owns the game and what type of license they have) and decided to keep an eye on it while focusing on the most likely offenders.
-----
By 17:20 UTC, we decided to restart the authentication system, which seemed to be at the heart of the issues. In hindsight, this was a mistake. With players already facing login problems and constantly retrying, restarting the system exacerbated the issue. We ended up needing to close off all authentication requests temporarily to allow the system to stabilize, and as the game needs to refresh its authentication tokens regularly, this meant that over time all players were unable to continue playing.
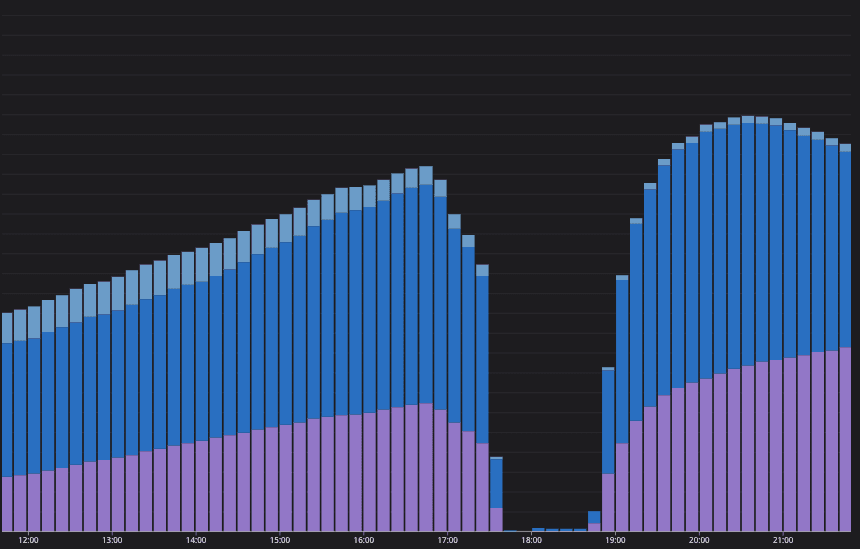
Users playing across our three regions.
Troubles started at 16:45 UTC, and were subsequently made much worse by ourselves at 17:20 UTC
----
With our authentication system back on its feet, we decided to re-allow all requests to the system. As we now had all our players attempting to log in simultaneously, the previously noticed problem with the entitlement system became glaringly obvious. The system was overwhelmed and went completely offline, meaning even those users who managed to connect appeared as if they no longer owned the game. At this point, we knew that we needed to fight on two fronts at the same time. The issue with the entitlements system couldn’t wait for the root cause behind the disconnections to be resolved. Thankfully, we were on the verge of solving this one.
---
So, what triggered this bombardment you will ask? Unfortunately, it was a self-inflicted wound. During our diagnosis, we found that some DNS hostnames were not resolving correctly. One of the engineers on the call had identified the problem - a missing DNS record, specifically a critical NS delegation record. Another engineer immediately realized what had happened.
Earlier in the day, a cleanup task involved removing unnecessary infrastructure, and this crucial record had been mistakenly deleted. The last commands in the cleanup had been issued around 16:40, and it so happens that the default TTL (time-to-live) for many DNS records is exactly 5 minutes. A few manual steps later, the record was recreated, and we had to wait patiently for DNS caches around the world to update.
--
The root cause, however, is only the triggering moment, and with the on-call staff in our War Room assessing the situation and a couple of senior backend engineers ready for action, we still needed to tackle the entitlement service issue. We decided to fight it from two fronts at the same time:
- The escalation and support route. We contacted and escalated the issue up the support chain of the provider responsible for our entitlement storage. They confirmed they were overwhelmed and promised a solution would be deployed soon. The clock started ticking at 17:40 UTC.
- The hotfix path. We modified our entitlement code to include a fallback method favoring our players. If we had issues resolving entitlements, but the player had previously owned a certain license type, we would assume they still did and let them pass. We already had a code path similar to this one, but it was handling the case of being rate-limited. Adding the case to have a similar result for when the entitlement service was unresponsive was an easy task, and the hotfix was reviewed, compiled, built, and rolled out within 10 minutes.
-
We now had three racehorses competing in the same race: our hotfix letting players in while the service suffered, the entitlement service itself stabilizing with fewer requests coming in and fixes being deployed, and the DNS caches worldwide updating to recognize the recreated record.
By 18:35 UTC, the situation had vastly improved. Our players were logging in successfully, the entitlement system was catching up, DNS propagation was nearing completion, and the War Room team had turned a dire situation around.
The DNS Debacle had been resolved, and we were ready for the next challenge on the horizon.